Dr Patrick Lucey is the Chief Scientist at Stats Perform and has over 20 years of experience working in Artificial Intelligence (AI), in particular face recognition and audio visual speech recognition technology. He also worked at Disney Research (owners of ESPN) where he developed an automatic sports broadcasting system that tracked players in real-time by moving a robotic camera to capture their movements.
Patrick recently talked about the use of Artificial Intelligence in sports, what that means and how we can use AI to help coaches and analysts make better decisions in sport. Artificial Intelligence refers to technology that emulates human tasks, often using machine learning as the method to learn from data how to emulate these tasks. His talk emphasised on the importance of sports data, and provided an overview on the different types of sports data that exist today. Patrick explained what is meant by AI and why is AI needed in sport.
Stats Perform is one of the leaders in data collection in sports, offering a wide range of sports predictions and insights through world-class data and AI solutions. For over 40 years, they have been collecting the world’s deepest sports data, covering over 27,000 live streamed events worldwide with a total of 501,000 matches covered annually from 3,900 competitions. This huge coverage translates into the collection of billions of unique event and tracking data points available in their immense sports databases. To make use of this invaluable dataset, Stats Perform has created an AI Innovation Centre that hired more than 300 developers and 50 data scientists to create a series of AI products with the goal of measuring what was once immeasurable in sport.
Different Types Of Sports Data
Patrick and the Stats Perform AI Innovation Centre have worked on a wide range of different types of data to make predictions on a number of different sports, from football to field hockey, volleyball to swimming using different types of data. There are 3 main types of sports data available: box scores, event data and tracking data. All these types of data facilitate the reconstruction of the story of a match or a particular performance. However, the more granular the temporal and spacial data of a game is, the better the story an analyst can tell.
Box-Score Statistics
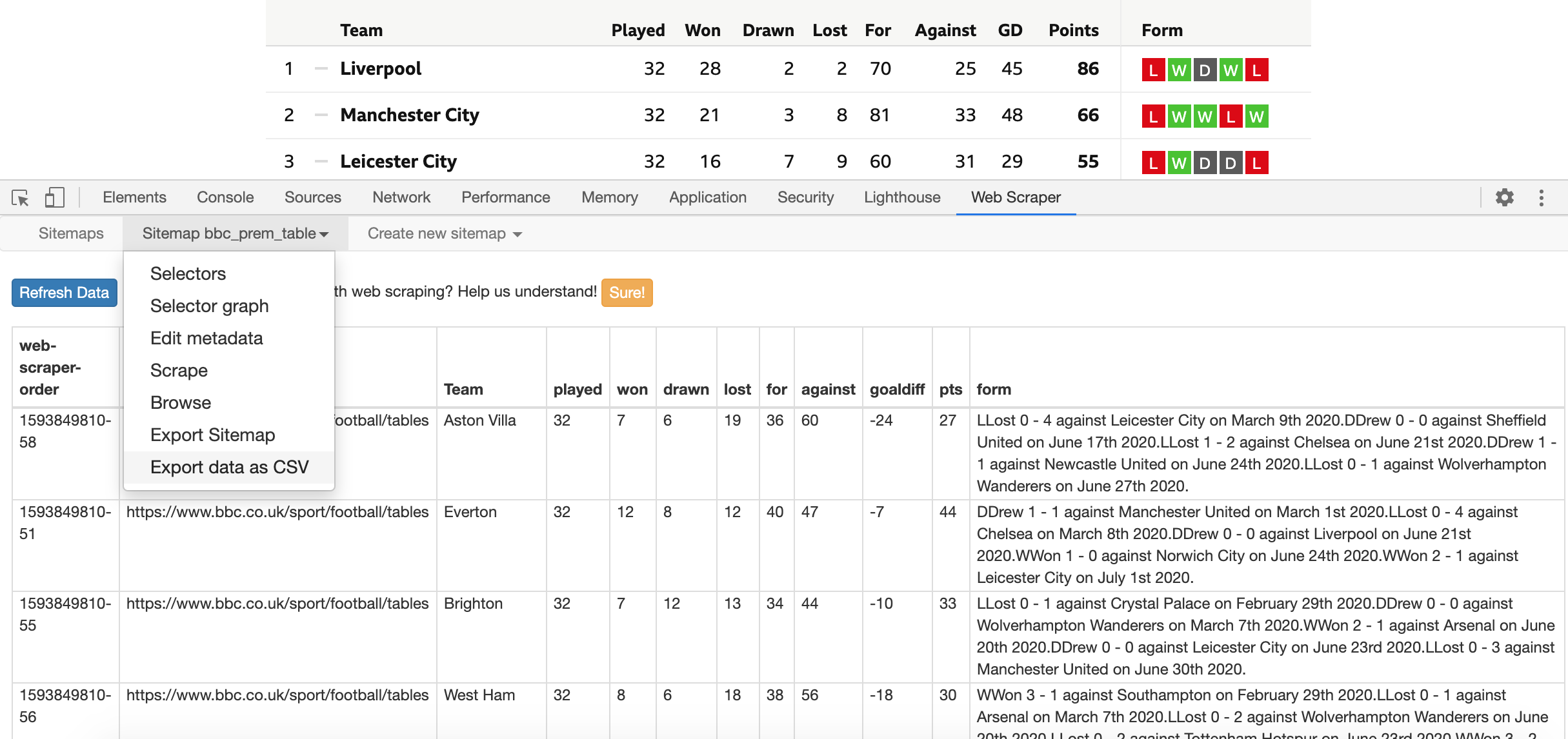
The use of high-level box-score statistics (half-time match score, full-time match score, goal scorers, time of goals, yellow cards, etc.) can summarise a 90-minute match of football to provide an idea on how the game was played in just a few seconds. Basic box-score statistics can tell you who won the match, which team took the lead first, when were the goals scored and how close together to each other. Box-score statistics provide a fairly good snapshot of a game and a decent level of match reconstruction.

Box-score statistics Sevilla vs Dortmund (Source: Sky Sports)
Box-score statistics also offer a more detailed level of information. For example, they can illustrate which team had more shots and the quality of those shots by showing the number of shots and shots on goal. They can also explain the distribution of possession between the teams in the match, which team had more corners, committed more fouls, made more saves and so on. Within a few second they can capture the story of the match, which team dominated or how close was that game.
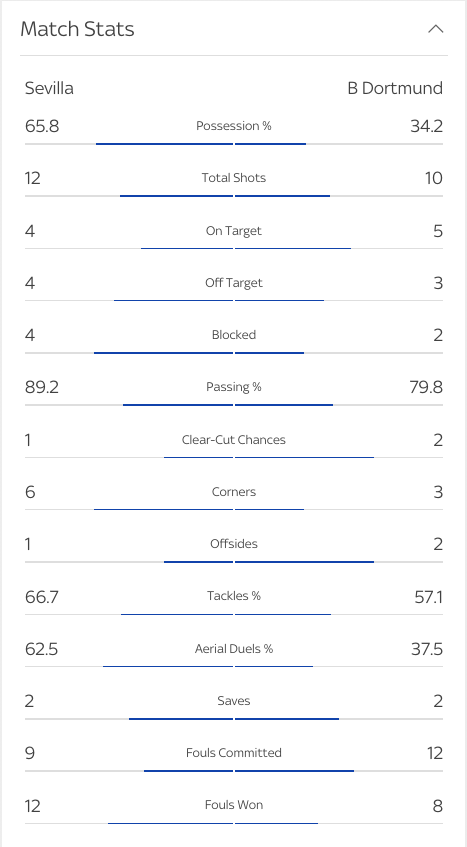
Detailed box-score statistics Sevilla vs Dortmund (Source: Sky Sports)
Event Data
Event data, or play-by-play data, provides a bit more detail than box-score statistics by offering additional contextual information of key moments during a match. For examples, play-by-play commentary of a match can offer textual descriptions of what occurred at every minute of the match. Similarly, spacial data of the game (i.e. spacial location of players) can provide visual reconstructions of some of the key events in a match, such as how a particular goal was scored. While it is not the same as watching the video, it is a quick digitised view of the real-world play that can be reconstructed in seconds.

Text commentary of Sevilla vs Dortmund match (Source: Sky Sports)
Stats Perform, particularly through Opta, is one of the industry leaders in event data collection. They provide event data to sportsbooks through a low latency feed that tells them when a goal, a shot, a dangerous attack or any other key moments occur in close-to-real-time so that the sportbooks can relay that information to their bettors. In these cases, speed of data is crucial, not only to reconstruct a story of what happens on the field through data but to be able to tell that story almost imminently.
Tracking Data
Tracking data is currently the most detailed level of data being captured in sports. It enables the projection of the location of all players and the ball into a diagram of the pitch that best reconstructs a match from the raw video footage of that match. Having a digital representation through tracking data of all players on the entire pitch enables analysts to perform better querying than simply using a video feed that only displays a subsection of the pitch.

Tracking data plotted into a diagram of a football pitch (Source: Patrick Lucey at Stats Perform)
Sources Of Sports Data
Video Footage
The vast majority of data types are collected via video analysis. Video analysis uses raw match footage as the foundation to either manually observe or automatically capture (i.e. computer vision) key events of the match to generate data from. Today, all three types of sports data (box-score, event data and player tracking data) are fundamentally based on video. However, more recently new technologies have been gradually introduced into various sports to collect great details.
Radio Frequency Identification (RFID)
The NFL is now using Radio Frequency Identification (RFID) wearables implemented on players’ shoulder pads to track x and y coordinates of each player’s location on the field.
Radar
In golf, radar and other sensor technology has also been implemented to track the ball’s trajectory and produce amazing visualisations with very accurate detection of the ball.
GPS Wearables
Football and other team sports use GPS devices that, although not as accurate as RFID, can track additional data from the athlete, such as heart rate and level of exertion. These wearable devices have the advantage that they can be used in a training environment as well as a competitive match.
Market Data (Wisdom Of The Crowds)
Market data in sports usually refers to betting data. It is an implicit way of reconstructing the story of the match that relies on people coming up with their predictions where information can be mined from.
AI-Driven Sports Analysis
Sports analysis has traditionally been based on box-score and event data. All the way from Bill James’ 1981 grassroots campaign Project Scoresheet that aimed to create a network of fans to collect and distribute baseball information to Daryl Morey’s integration of advanced statistical analysis in the Houston Rockets in 2007.
However, in the 2010s, tracking data began to set a new path to new ways of analysing sports. Over the last decade, a new era of sports analysis has emerged that maximises the value of traditional box-score and event data by complementing it using deeper tracking data. The AI revolution in sports thanks to tracking data has focused on three key areas:
Collecting deeper data using computer vision or wearables
Performing a deeper type analysis with that tracking data that humans would not be able to do without AI
Performing deeper forecasting to obtain better predictions
Collecting Deeper Sports Data
The main objective of collecting sports data is to reconstruct the story of a match as closely as possible to the one seen by the raw footage that a human or a camera can see. The raw data collected from this footage can then be transformed into a digitised form so that we can read and understand the story of the match and produce some actionable insights.
The reconstruction of a performance with data usually starts by segmenting a game into digestible parts, such as possessions. For each part of this game, we try to understand what happened in that possession (i.e. what was the final outcome of the possession), how it happened (i.e. describing the events that led to the outcome of that possession) and how well it was done (i.e. how well were the events executed).
Currently, the way play-by-play sports data is digitised from the video footage is through the work of video analysts. Humans watch a game and notate the events that take place in the video (or live in the sports venue) as they happen. This play-by-play method of collecting data produces an account of end of possession events that describes what happened on a particular play or possession. However, when it comes to understanding how that play happened or how well it was executed, human notational systems do not produce the best information to accurately reconstruct the story. Humans have cognitive and subjective limitations when capturing very granular level of information manually, such as getting the precise timeframe of each event or providing objective evaluation of how well a play was executed.
In-Venue Tracking Systems
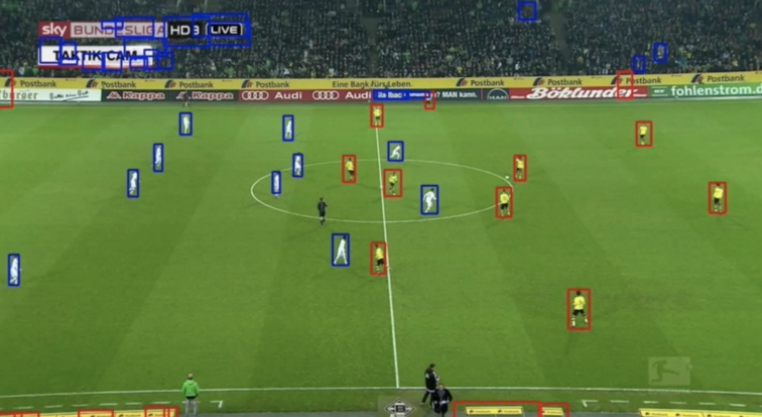
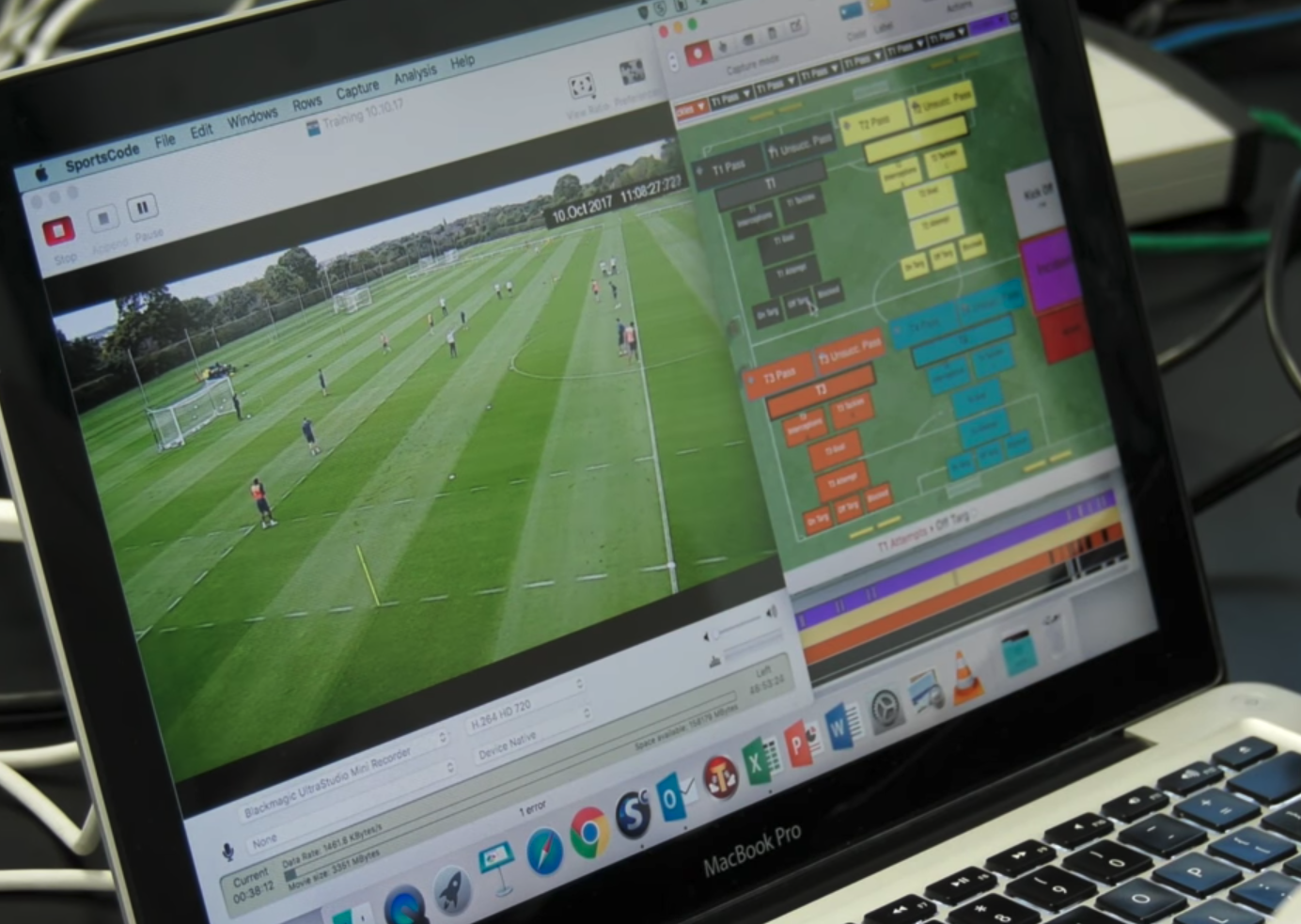
One way tracking data can be collected is through in-venue systems. Stats Perform uses SportVU, which was deployed a decade ago as a computer vision system that installed 6 fixed-cameras on a basketball court to track players at 24 frames per second. Their newer version of SportVU is now widely deployed in football. SportVU 2.0 uses three 4K cameras and a GPU server in-venue to collect and deliver tracking data at the edge in real-time.

Stats Perform SportVU system on a basketball court (Source: Patrick Lucey at Stats Perform)
However, tracking data has a main limitation: coverage. While tracking data provides an immense number of opportunities to do advanced sports analytics, its footprint across most sports is relatively low. This is because for most in-venue solutions a company like Stats Perform requires to be in the venue with all their tracking equipment installed. This is problematic when increasing the coverage of tracking data across multiple events across the world, as it is not realistic to have sophisticated tracking equipment installed in every single pitch, field, court or stadium across the world to cover every single sporting event that takes place every day.
Tracking Data Directly From Broadcast Video
To overcome the limited coverage of in-venue systems, Stats Perform are now focusing their AI efforts in capturing tracking data directly from broadcast video, through an initiative called AutoStats. It leverages the fact that for every sports game being played, there should be at least one video footage of that event being recorded and potentially being broadcasted. The way of getting the best coverage of tracking data is capturing the data directly from broadcasting footage.
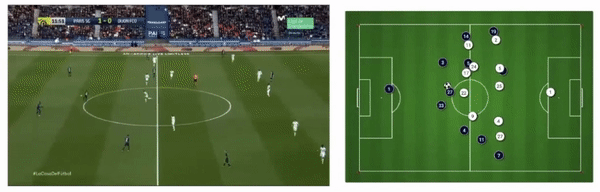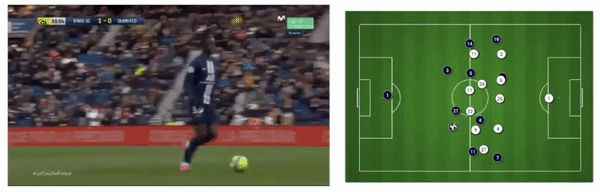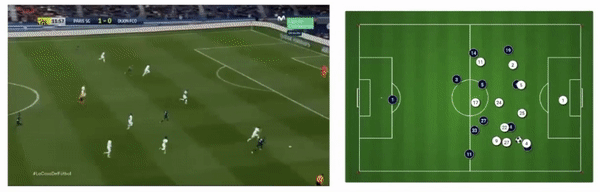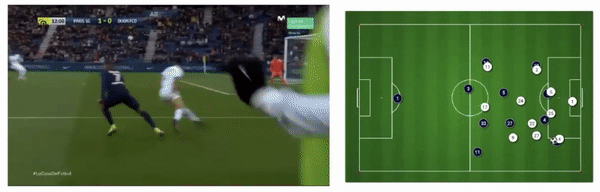
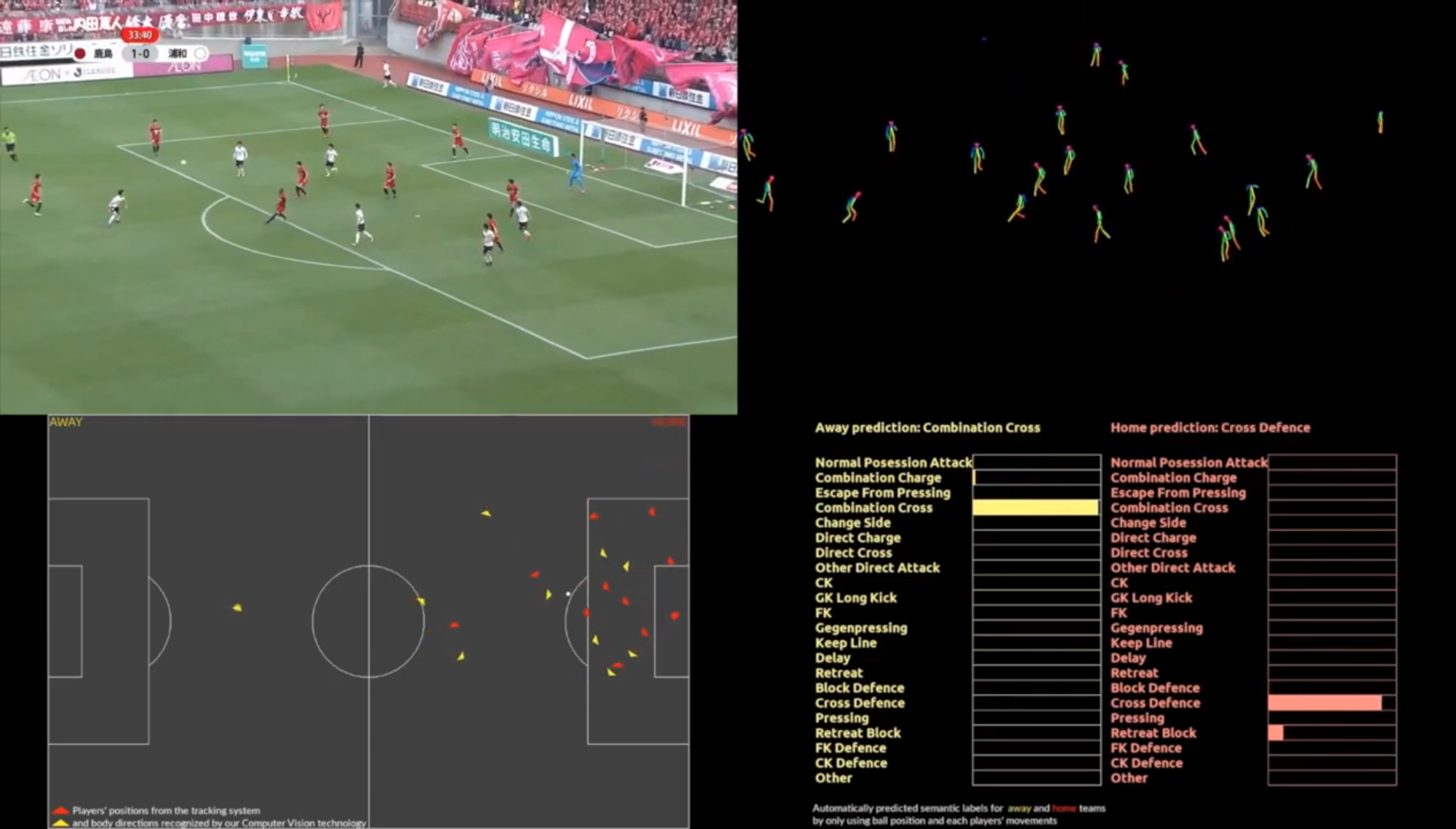
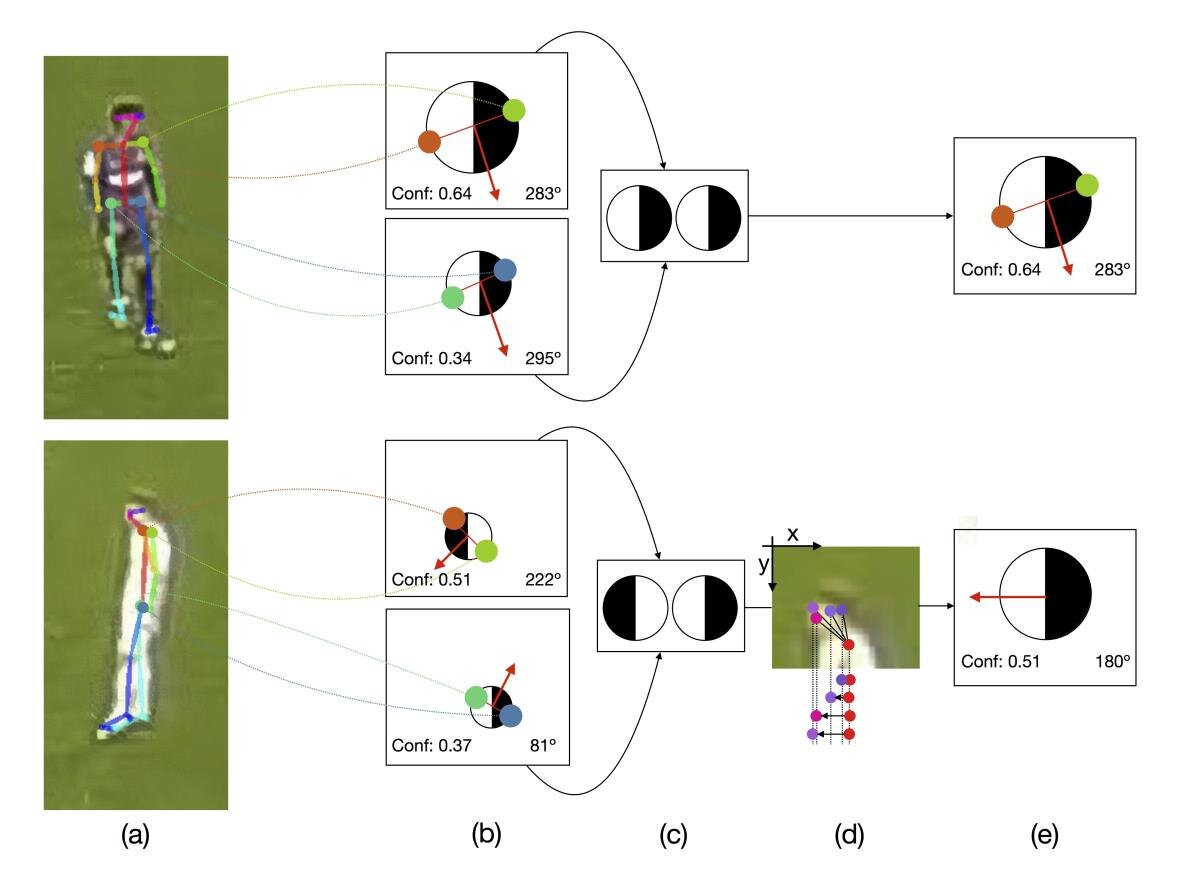
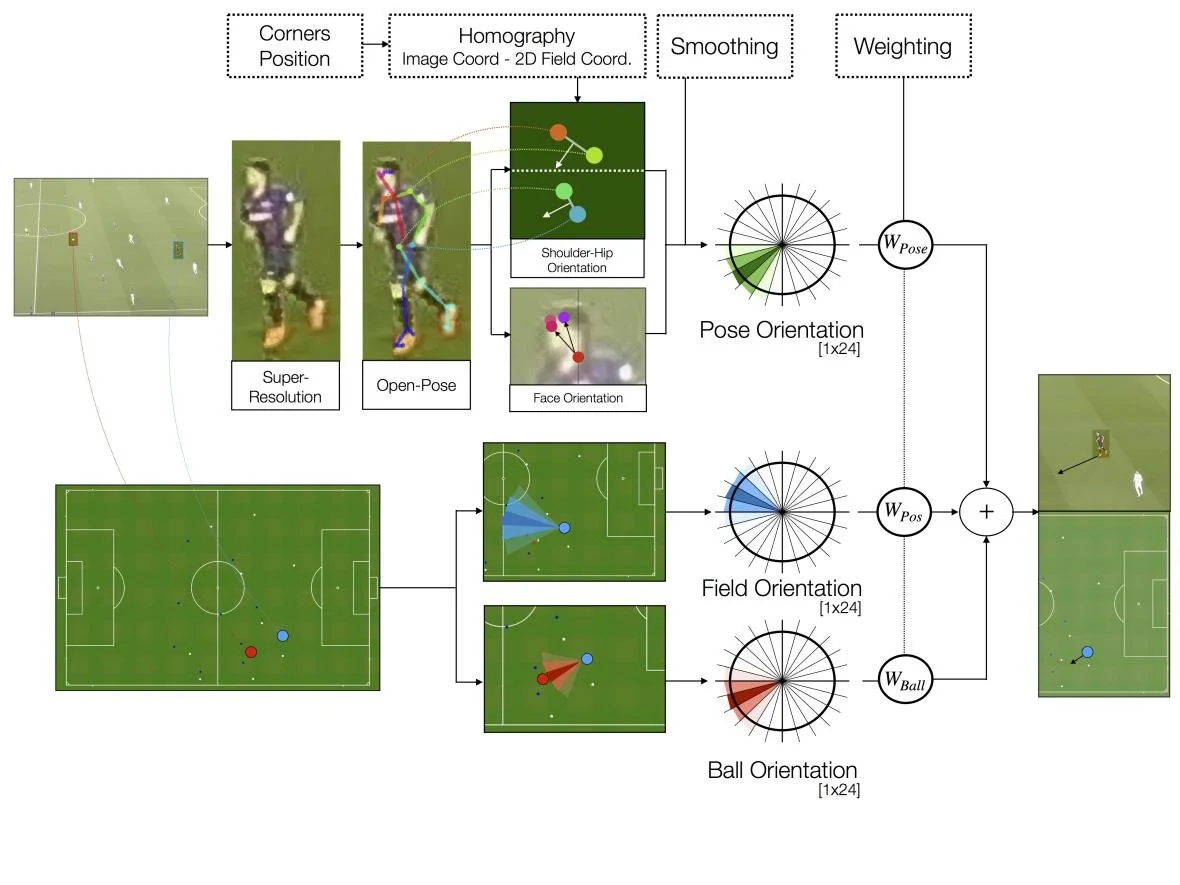
PSG attacking play converted to tracking data from broadcast footage (Source: Patrick Lucey at Stats Perform)
This means that the way tracking data is being collected is now evolving away from in-venue solutions to a more widespread approach that uses a broadcast camera. However, the advantage of using in-venue solutions is that you only need to calibrate the camera once. When collecting tracking data off broadcast, you need to calibrate the camera at every frame because it is constantly moving while following the play.
Computer vision systems that collect tracking data directly from broadcasted video footage follow three simple steps:
Transform pixels in the video into dots that represent trajectories of the movement of players and the ball. These dots can then be plotted on a diagram of the field for visualisation.
The trajectories generated from the movement of the dots over a space of time can then be mapped to semantic events in the sport (i.e. a shot on goal).
From the events identified, expected metrics can be derived to explain how well does a player execute on a particular event (i.e. Expected Goals).
Converting Pixels To Dots
Converting video pixels to dots refers the process of taking the video footage of the game and digitally mapping each player movement to trajectories that can be displayed on a diagram of the pitch in the form of dots. The main advantage of this method is the compression of the footage. An uncompress raw snapshot image of a game at 1920x1080px from a single camera angle can be as large as 50MB, which means video footage of that game can be as large as 50MB per frame. If instead of one camera angle you have 6 different camera angles, the data file size multiplies to around 300MB per frame. This is an incredibly high amount of high dimensional data, but not all of it is useful for sports analysis.
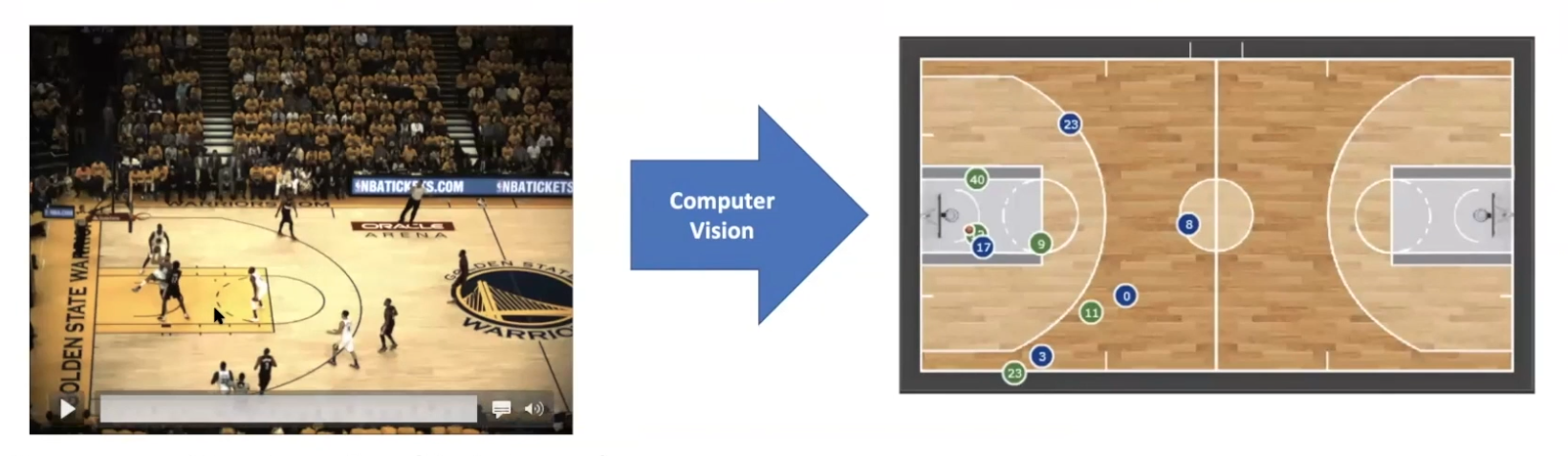
Conversion of video footage pixels into dots on a diagram (Source: Patrick Lucey at Stats Perform)
Instead, tracking data representing players on the court or pitch in the form of dots can substantially reduce the size of each frame. For example, in basketball, 10 players, 1 ball and 3 referees can be plotted with their x, y and z coordinates in a digital representation of the court with a size of 232 bytes per frame. This makes tracking data the master compression algorithm on sports video with compression rates of 1 million to 1.
The advantages of using tracking data instead of raw video footage is that it allows to query the dots instead of the pixels in a way that maintains the interpretability and interactivity from the raw video footage. A game can be clearly reconstructed using dots plotted on a diagram of the field to illustrate how each possession happened without the need of the extra detail available in the video footage in the form of millions of pixels.
The way the conversion from pixels to dots occur is via supervised learning, where the computer learns through machine learning processes to map and predict the input data from the pixels to the desired output of the dots. A number of computer vision techniques can be applied to achieve this goal.
Mapping Dots to Events
Once the dots (coordinates) have been generated from the pixel data of the video, the trajectories (movements) of these dots over specific timeframes can be mapped to particular events. For example, in basketball, you can start mapping these dots in the tracking data to particular basketball-related events that describe how certain outcomes occur in terms of tactical themes, such as pick and roll, type of coverages on pick and roll, did the player do a drive or a post up, off-ball screens, hand off, close out, etc. The dot trajectories are mapped to the semantics of a basketball play, and the players involved in that play, using a machine learning model that does that transformation using pre-labelled data.
Mapping Events to Expected Metrics
Expected metrics explain the quality of execution of certain events. The labels assigned to certain events are often not informative enough to explain that event. Instead, expected metrics transform an outcome label of 0 or 1 (goal or no goal) to a probability of 0 to 100% using machine learning. For example, a shot that goes in goal is considered 100% effective. However, a shot attempt that hits the post might be considered 70% effective, even if it did not end up in a goal. Regardless of the final outcome of that event, expected metrics help to evaluate whether an event was more likely to be 0% (unsuccessful), 100% (successful) or somewhere in the middle (ie. 55% successful). This concept of expected metrics is the basis of the Expected Goals (xG) metric in football. Expected Goals can also be extended to passes to calculate the likelihood of a pass reaching a certain teammate on the pitch.
Expected metrics provide an additional degree of context to each situation. For example, in basketball they use Expected Field Goal percentage (EFG) to explain that if a player misses a 3-point shot, rather than simply classify that player as missing a shot we can assess what is the likelihood that an average league player would have scored that shot from a similar situation. This can provide a measure of talent of a player over the league average and better contextualise his performance.
Limitations of Event and Expected Metrics Data
The main limitation of solely using pre-labelled event and expected metrics data using this supervised machine learning process is that not everything can be digitised. Most analysis conducted today are based on events and expected metrics, but these are semantic layers that have been pre-described or pre-categorised by humans. We have put certain patterns of play or combination of player movements into labelled boxes to make it easy to aggregate and analyse sport events. However, the dots generated from tracking data and their identified trajectories open numerous possibilities to perform further analysis that humans can’t do manually by ignoring these pre-labelled categories of patterns of play or specific player movements.
Performing Deeper Sports Analysis
The more granular the data the better analysis we can conduct of a sport. Tracking data provides that necessary level of granularity to conduct advanced analytics. Some of the key tasks that deeper data and better metrics can do much better than humans is strategy, search and simulation.
Strategy Analysis
Marcelo Bielsa once broke down the way he does analysis at Leeds United. His analysis team watches all 51 matches of their upcoming opponent from the current and prior seasons, each game taking 4 hours to analyse. In that analysis, they look for specific information about the team’s starting XI, the tactical system and formations and the strategic decisions that they make on set pieces. However, it can be argued that this methodology is time-consuming, subjective and often inaccurate. This is where technology can come in and help by making the analysis process more efficient than having a team of Performance Analysts spend 200 hours assessing the next opponent.
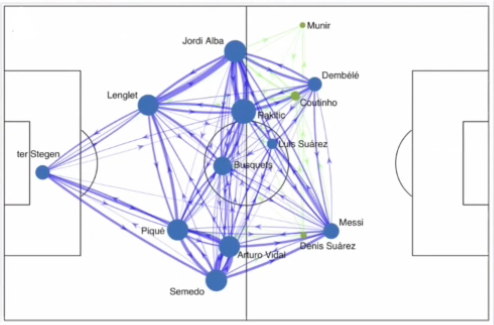
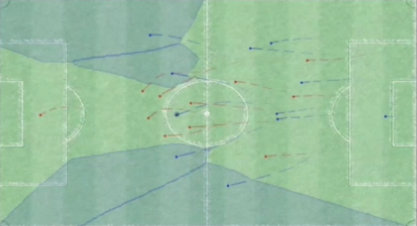
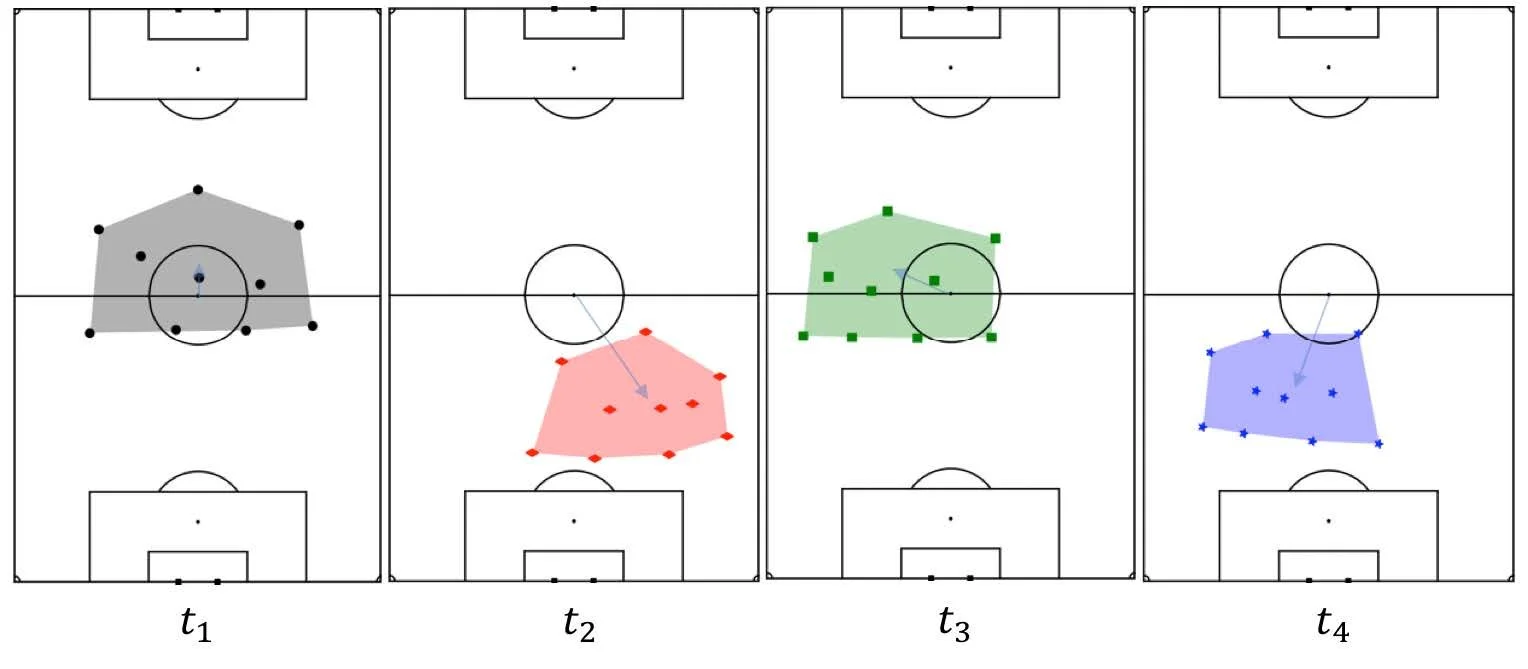
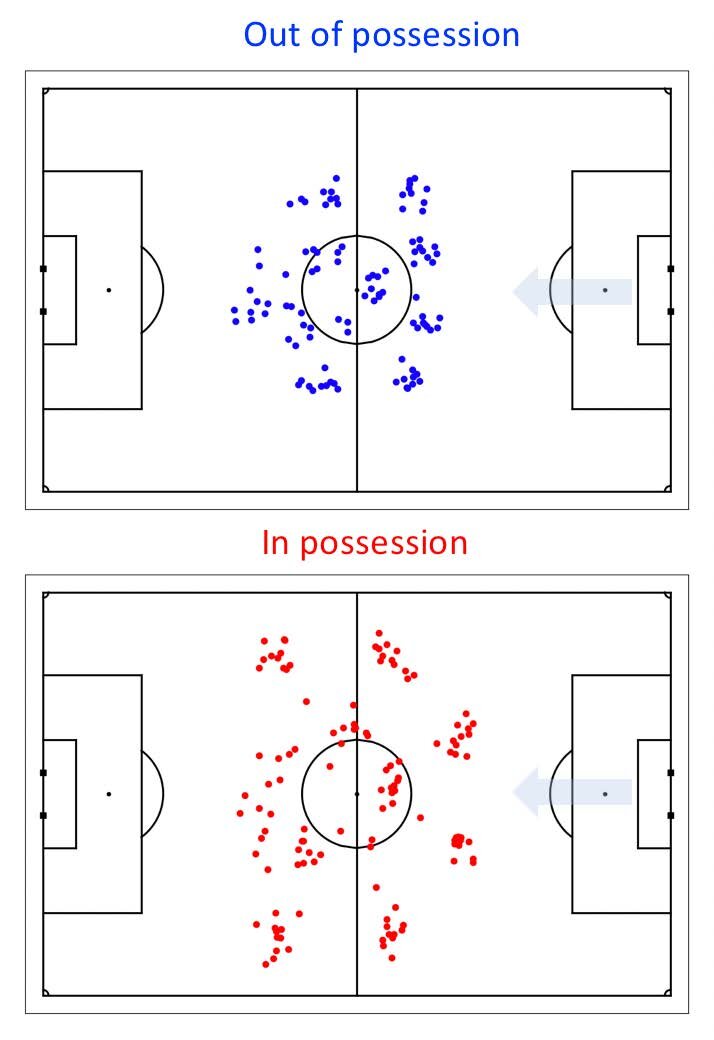
The idea is to transition strategy analysis in sports from a traditional qualitative approach to a more quantitative method. Tracking data has hidden structures. The strategies and formations of a team in a match of football is hidden within all the data points collected from tracking data. Insights on things like formation or team structures do not directly emerge from the tracking data without additional work on the data. This is because tracking data is noisy, for reasons such as that players are constantly switching positions on the pitch. But what tracking data allows you to do is to find that hidden behaviour and structure of a team or players and let it emerge.

Visual representation of a noisy tracking dataset of players in a football pitch (Source: Patrick Lucey at Stats Perform)
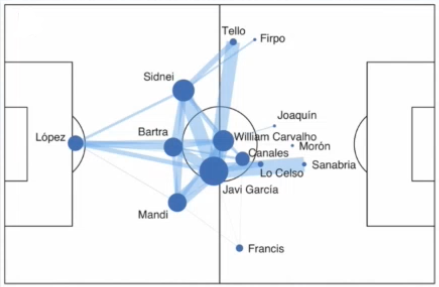
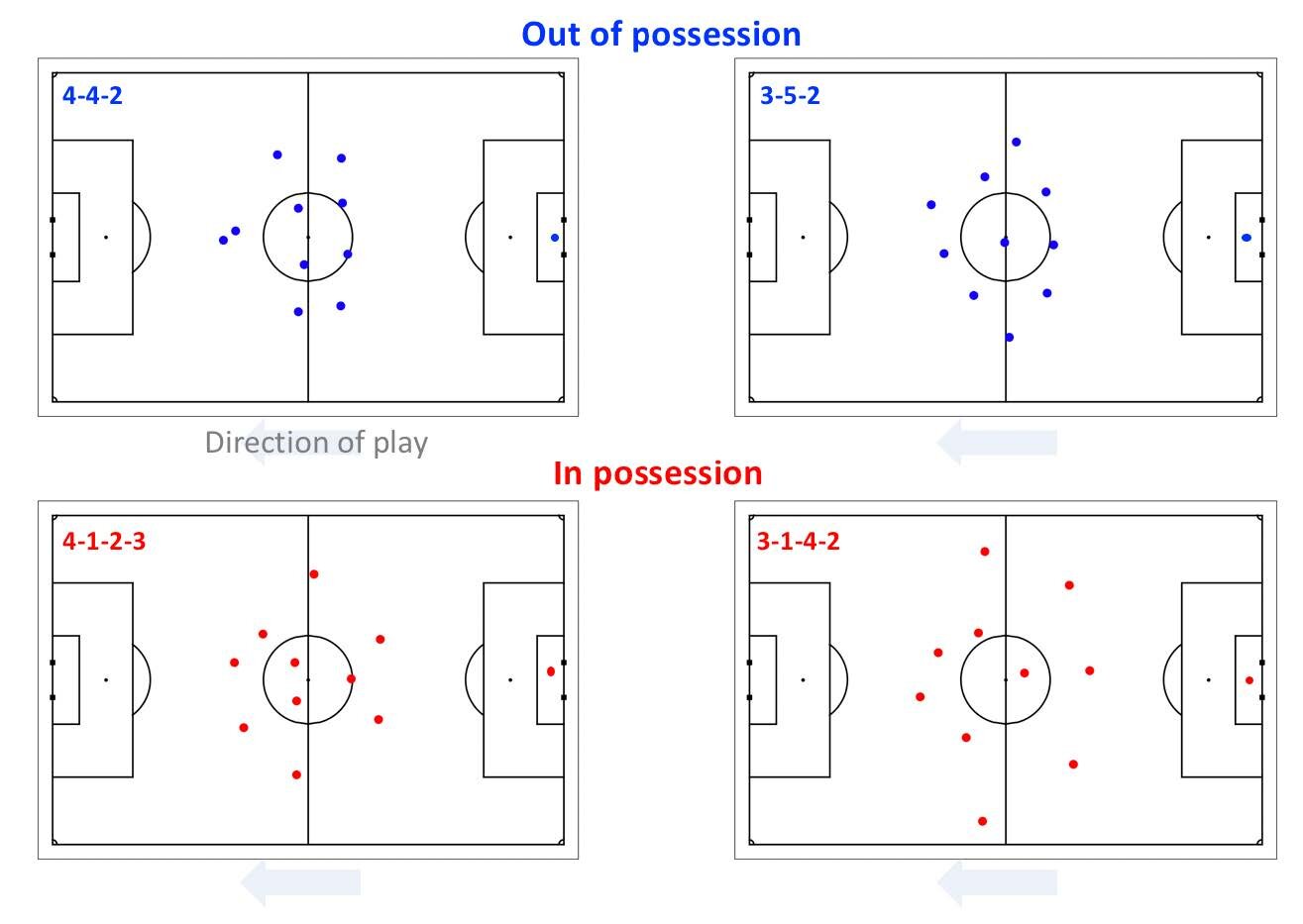
As a way to better visualise and interpret tracking data, Stats Perform have developed the software solution Stats Edge Analysis to enable the querying of infinite formations based on tracking data. The software shows the average formation of players throughout a match, how often each player is in a certain situation, how a team’s structure evolve when they are attacking or defending or how does the formation compare in different context, situations or playing styles.

Formation analysis in Stats Edge Analysis software (Source: Patrick Lucey at Stats Perform)
Search Analysis
How do we find similar plays in sport? How do we search across the history of a sport to find similar situations to the one we are interested in comparing with? One way is to use sport semantics and search using keywords such as a “3pt shot” play in basketball, a “pick and pop” play or a play “on top of the 3pt line”. However, if we want to know where all the players were located in a play, their velocity or their acceleration, as well as all the events that led up to that point, we would need to use too many words to describe that particular play very precisely. In other words, searching across the history of a sport for a similar play using just keywords does not capture the fine-grained location and motions of players and ball and does not provide a ranking of how similar the found plays are to the original play we want to compare them with.
A solution to this problem is to use tracking data. Tracking data is a low dimensional representation of what we see in video. Therefore, instead of using keywords to find a similar play, we could use a snapshot of a play using tracking data as the input in a visual search query. Users could then interact with a visual search query where they describe the type of play they want to search for and the query tool would then output a set of similar plays ranked by the degree of similarity to the play being queried.
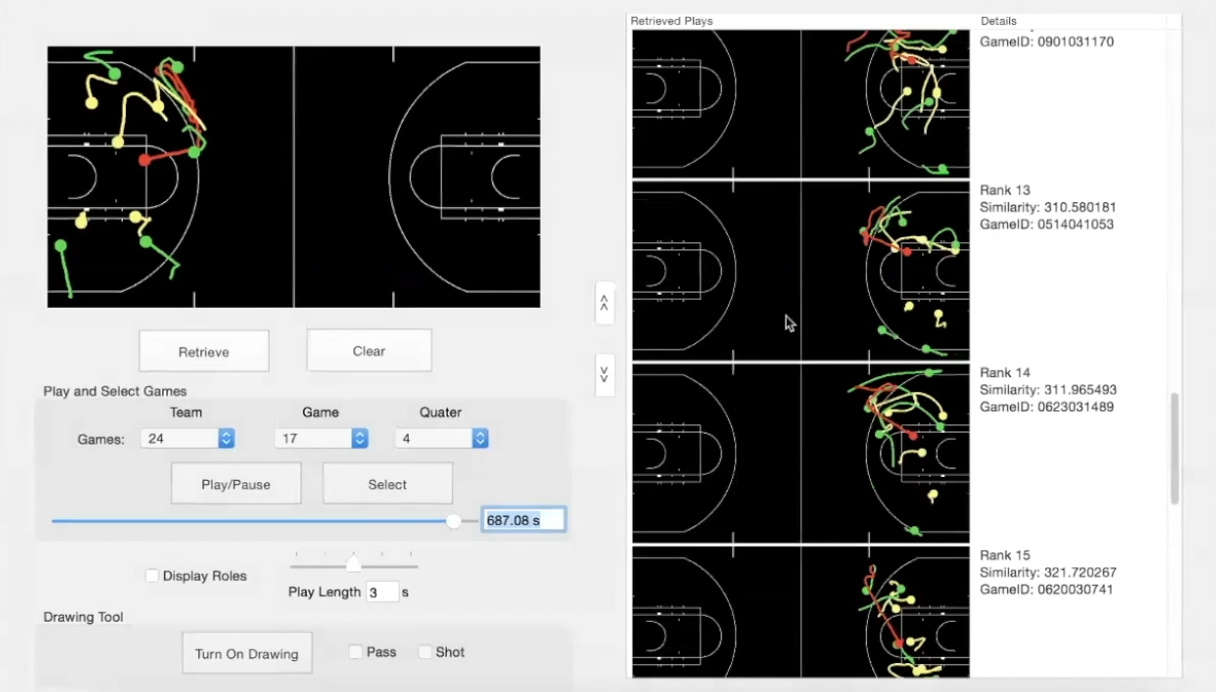
Visual search query of similar plays (Source: Patrick Lucey at Stats Perform)
This type of visual search tool based on tracking data can offer the possibility of drawing out the play to search for. It can also offer the ability to move players around the court and use expected metrics to show the likelihood of a player scoring from various positions. It can even show the changes in scoring likelihood based on the position of the defensive players relative to the player with the ball.
Play Simulation
Technology in sports is entering the sidelines. The type of technology coaches need to evaluate plays during a game and simulate different outcomes needs to be highly interactive. One way Stats Perform has used tracking data to improve play simulations is through ghosting. The idea of ghosting is to show the average play movements at the same time as the live play represented with dots on a diagram of the field. For example, tracking data can display the home team in one colour (blue) and away team in another colour (red), but additionally it can add a third defensive team in a different colour (white) that represents how the average team in the league would defend that same situation.
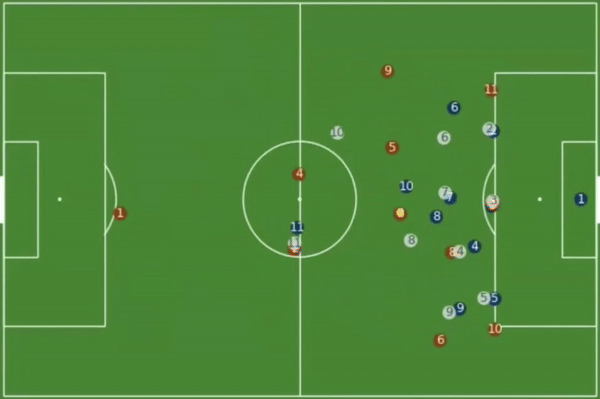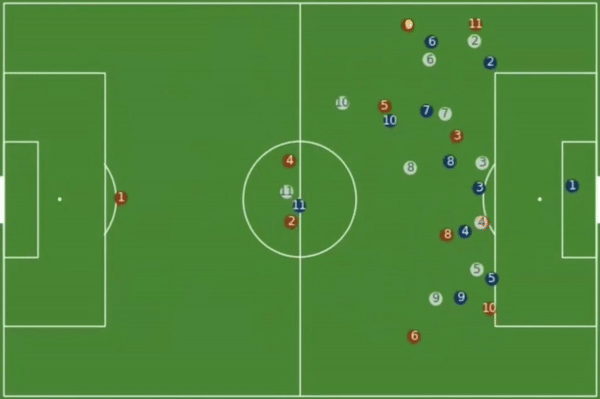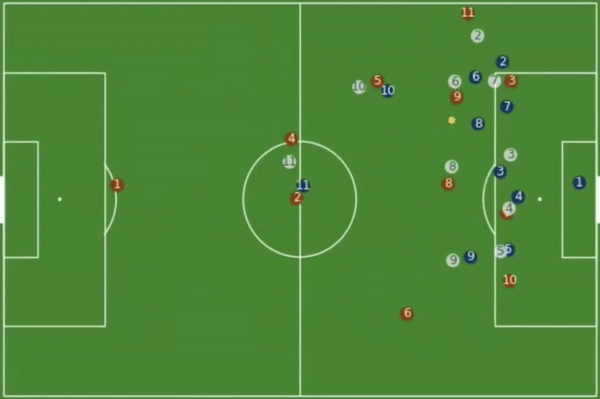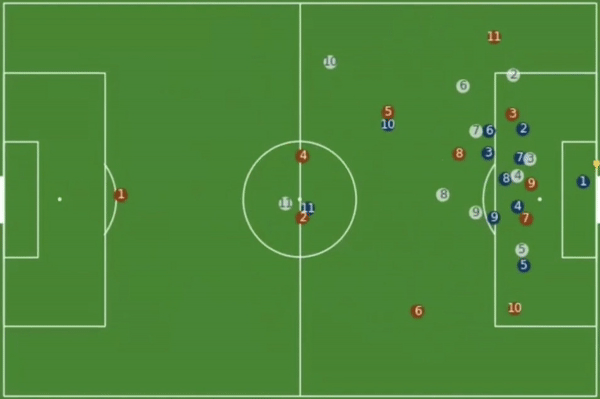
Ghosting of an average team in the league (white) defending a situation (Source: Patrick Lucey at Stats Perform)
Another way Stats Perform is working with coaches in the sidelines to provide more interactive play simulations is through real-time interactive play sketching. A coach can draw out a play that they want their players to perform on their clipboard and what tracking data and technology can do is to make intelligent clipboards that can simulate how that play drawn by the coach would play out.
Performing Deeper Sports Forecasting
The more granular data available the better we can predict sports performance. Some of the applications of tracking data in forecasting include player recruitment (i.e. which players to buy, trade, draft or offer longer contracts) and match predictions (i.e. accurately predict the final outcome, score and statistics of a match both before the match takes place and in-play).
Player Recruitment
In the NBA, the league has a good level of coverage for tracking data. But what happens when a team wants to recruit someone from college? Tracking data might not exists in college leagues, which forces teams to use a very simplified version of reporting to forecast how that player is going to play once he is recruited onto the team.
This highlights the issue of tracking data coverage. Major leagues have that level of detailed tracking data, but most lower leagues and academy competitions do not. Also, historical matches from major leagues and sports prior to the era of tracking data will not have had the systems and equipment in place at the time to produce highly detailed tracking data. This is where the generation of tracking data through broadcasted video footage can fill that void.
Tracking data using broadcasting footage is the ultimate method to produce detailed recruitment data. Analysts can go back in time and produce data from all the previously untracked players by simply using the footage available from past games. Stats Perform achieves this through AutoStats. AutoStats is a data capture system that can identify where players are located even though the camera is constantly moving by applying continuous camera calibration. It detects body pose of players and can re-identify a player once that player comes back into view after having left the frame. Additionally, AutoStats uses optical character recognition to collect the game and shot clock on every frame, as well as using action recognition to track the duration of player events at a frame-level.
Once that tracking data has been generated from lower leagues or college games, AI-based forecasting can be applied to discover which other professional players is the scouted player of interest most similar to. These solutions can even project a young player’s future career performance. It can use prediction models from historical data of former rookies and their eventual successes to forecast future performances of current prospects.
Given the limited coverage of tracking data in lower and junior leagues, another method to overcome that limitation is to use the already collected event data to maximise the value of the coverage in event data compared to tracking data. Machine learning can define the specific attributes of two players to then compare them with each other. These attributes can be spacial attributes, such as where they normally receive the ball, contextual attributes, such as their team’s playing style (i.e. frequency of counter attacks, high press, crossings, direct plays, build up plays, etc.) and quality attributes, such as expected metrics to capture the value and talent of each player. This method can provide a clear comparison of two different players relative to the context in which they play in. For example, how often is a player involved relative to the playing style of a particular situation.
Taking all this data and the derived attributes from event data, you can then run unsupervised models, such as Gaussian mixture model clustering, to discover groupings of players based on their similarities, and then create a number of unique player clusters that divide pools of players. These clusters can then surface information about the roles that different groups of players play in their teams, whether they are “zone-movers”, “playmakers”, “risk-takers”, “facilitators”, “conductors”, “ball-carriers” or any other clusters that can emerge from applying unsupervised methods. This way, if a team wants to find a player similar to a specific successful player (i.e. players similar to Messi), but with some attributes that are slightly different (i.e. age, league, etc.), they are able to specify that search criteria and find players that fit the profile that they are after.

Match Predictions
There are a couple of ways that AI can help in match predictions. One of them is implicitly through crowd-sourced data. Prediction markets like betting exchange facilitate a marketplace for customers to bet on the outcome of discrete events. It is a crowd-sourced method, and if there are enough participants to represent the entire collective wisdom of the market, with enough diversity of information and independence of decisions in a decentralised way, it is the best predictor you can get. It is an implicit market as we do not know the reason why people have made their betting choices, therefore it is not interpretable. If enough people are participating in these markets, then all possible information to make a prediction is present in that market. If that is the case, it is not possible to beat the accuracy of that market prediction.
Another method is to use an explicit data-driven approach using only data from historical matches together with machine learning techniques to predict probabilities of match outcomes. This method relies on the accuracy and depth of the data available and can only capture the performance present within the data points collected. The advantage of using a data-driven approach is that it can be interactive and interpretable. Also, it only needs the data feed of events, which makes it scalable. However, since not all data might be captured in the dataset used (i.e. injury data), there may be gaps in the analysis that can affect the predictions made.
Sportsbooks normally use a hybrid approach of crowd-sourced data together with data-driven methods to balance the action on both sides of the wager and also to manage their level of risk. They initialise the market with a data-driven approach and human intuition and then iterate based on volume, other sportbooks line and any unique incentive they want to offer to their own customers.
AI-based solutions and tracking data can be used to support these prediction markets, particularly in those markets with insufficient coverage to achieve crowd wisdom. One way of doing so is through the calculation of win probability. Win probability is extensively used across nearly every sport for media purposes. The current limitation of win probability is that it is based on the likelihood that an average team would win given a particular match situation. However, simply using an average may miss contextual information about the specific strengths of particular teams or players involved. The way to overcome that is to use specific models that incorporate the players, teams and line-ups of the match in question.
Stats Perform uses models that learn compact representations with features such as the specific opponent, players involved and other raw features describing the lineup to improve prediction performance based on the players involved in the game. This allows them to create specific player props that can predict individual player statistics (i.e. expected points scored in basketball) for each player in the lineup and illustrate that player’s future game performance before the game starts.
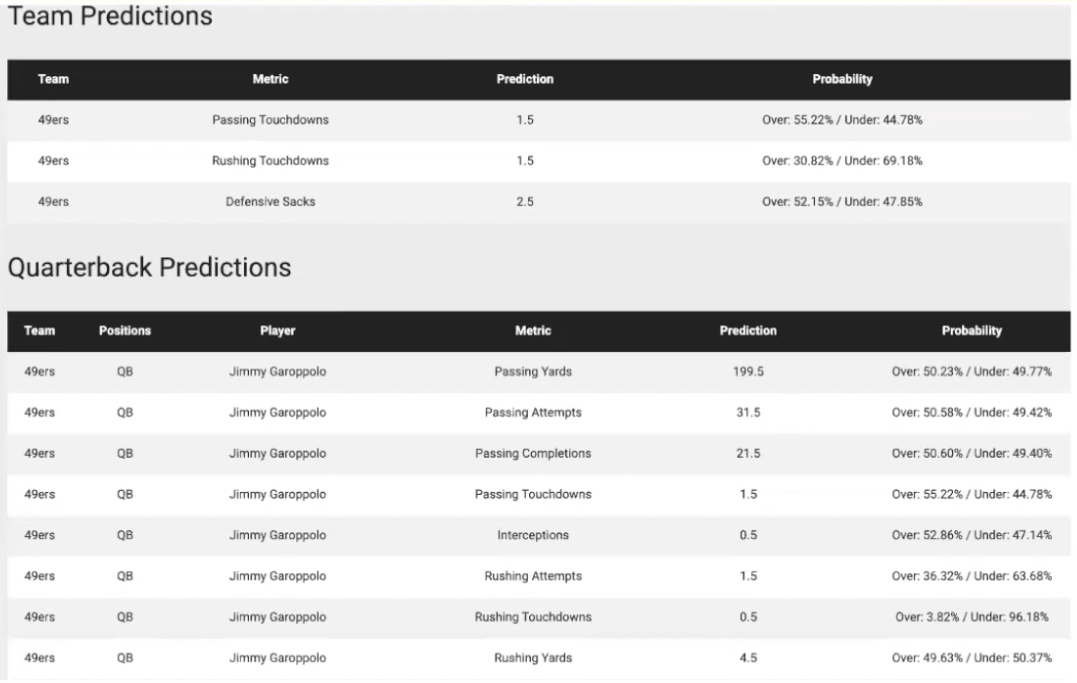
Similarly, these predictions can also be made in real-time while a match is being played. For example, using tracking data, in-play predictions in a tennis match can predict who is more likely to win the next point while the rally is taking place. You can even go a level deeper and predict what is the location where the ball will land after the next strike. In football, you could also predict who is the next player who is going to receive a the ball from a pass or where the next shot on goal is going to occur. This is the true value of highly granular levels of data and a data-driven approach to sports analysis.